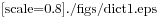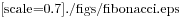Chapter 11 DizionariQuesto capitolo illustra un altro tipo predefinito chiamato dizionario. I dizionari sono una delle migliori caratteristiche di Python; sono i mattoni che costituiscono molti eleganti ed efficienti algoritmi. 11.1 Un dizionario è una mappaturaUn dizionario è simile ad una lista, ma è più generico. Infatti, mentre in una lista gli indici devono essere numeri interi, in un dizionario possono essere (quasi) di ogni tipo. Un dizionario contiene una raccolta di indici, chiamati chiavi, e una raccolta di valori. Ciascuna chiave è associata ad un unico valore. L’associazione tra una chiave e un valore è detta coppia chiave-valore o anche elemento. In linguaggio matematico, un dizionario rappresenta una relazione di corrispondenza, o mappatura, da una chiave a un valore, e si può dire pertanto che ogni chiave “mappa in” un valore. Come esempio, costruiamo un dizionario che trasforma le parole dall’inglese all’italiano, quindi chiavi e valori saranno tutte delle stringhe. La funzione dict crea un nuovo dizionario privo di elementi. Siccome dict è il nome di una funzione predefinita, è meglio evitare di usarlo come nome di variabile. >>> eng2it = dict()
>>> eng2it
{}
Le parentesi graffe, >>> eng2it['one'] = 'uno' Questa riga crea un elemento che contiene una corrispondenza dalla chiave
>>> eng2it
{'one': 'uno'}
Questo formato di output può essere anche usato per gli inserimenti. Ad esempio potete creare un nuovo dizionario con tre elementi: >>> eng2it = {'one': 'uno', 'two': 'due', 'three': 'tre'}
Se stampate ancora una volta eng2it, avrete una sorpresa: >>> eng2it
{'one': 'uno', 'three': 'tre', 'two': 'due'}
L’ordine delle coppie chiave-valore non è necessariamente lo stesso. Se scrivete lo stesso esempio nel vostro computer, potreste ottenere un altro risultato ancora. In genere, l’ordine degli elementi di un dizionario è imprevedibile. Ma questo non è un problema, perché gli elementi di un dizionario non sono indicizzati con degli indici numerici. Infatti, per cercare un valore si usano invece le chiavi: >>> eng2it['two'] 'due' La chiave Se la chiave non è contenuta nel dizionario, viene generato un errore:: >>> print(eng2it['four']) KeyError: 'four' La funzione len è applicabile ai dizionari, e restituisce il numero di coppie chiave-valore: >>> len(eng2it) 3 Anche l’operatore in funziona con i dizionari: informa se qualcosa compare come chiave nel dizionario (non è condizione sufficiente che sia contenuto come valore). >>> 'one' in eng2it True >>> 'uno' in eng2it False Per controllare invece se qualcosa compare come valore, potete usare il metodo values, che restituisce una raccolta dei valori, e quindi usare l’operatore in: >>> vals = eng2it.values() >>> 'uno' in vals True L’operatore in utilizza algoritmi diversi per liste e dizionari. Per le prime, ne ricerca gli elementi in base all’ordine, come nel Paragrafo 8.6. Se la lista si allunga, anche il tempo di ricerca si allunga in proporzione. Per i secondi, Python usa un algoritmo chiamato tabella hash che ha notevoli proprietà: l’operatore in impiega sempre circa lo stesso tempo, indipendentemente da quanti elementi contiene il dizionario. Rimando la spiegazione di come ciò sia possibile all’Appendice B.4: per capirla, occorre prima leggere qualche altro capitolo. 11.2 Il dizionario come raccolta di contatoriSupponiamo che vi venga data una stringa e che vogliate contare quante volte vi compare ciascuna lettera. Ci sono alcuni modi per farlo:
Ciascuna di queste opzioni esegue lo stesso calcolo, ma lo implementa in modo diverso. Un’implementazione è un modo per effettuare un’elaborazione. Le implementazioni non sono tutte uguali, alcune sono migliori di altre: per esempio, un vantaggio dell’implementazione con il dizionario è che non serve sapere in anticipo quali lettere ci siano nella stringa e quali no, dobbiamo solo fare spazio per le lettere che compariranno effettivamente. Ecco come potrebbe essere scritto il codice: def istogramma(s):
d = dict()
for c in s:
if c not in d:
d[c] = 1
else:
d[c] += 1
return d
Il nome di questa funzione è istogramma, che è un termine statistico per indicare un insieme di contatori (o frequenze). La prima riga della funzione crea un dizionario vuoto. Il ciclo for attraversa la stringa. Ad ogni ripetizione, se il carattere c non compare nel dizionario crea un nuovo elemento di chiave c e valore iniziale 1 (dato che incontra questa lettera per la prima volta). Se invece c è già presente, incrementa d[c] di una unità. Vediamo come funziona: >>> h = istogramma('brontosauro')
>>> h
{'a': 1, 'b': 1, 'o': 3, 'n': 1, 's': 1, 'r': 2, 'u': 1, 't': 1}
L’istogramma indica che le lettere I dizionari supportano il metodo get che richiede una chiave e un valore predefinito. Se la chiave è presente nel dizionario, get restituisce il suo valore corrispondente, altrimenti restituisce il valore predefinito. Per esempio: >>> h = istogramma('a')
>>> h
{'a': 1}
>>> h.get('a', 0)
1
>>> h.get('b', 0)
0
Come esercizio, usate get per scrivere istogramma in modo più compatto. Dovreste riuscire a fare a meno dell’istruzione if. 11.3 Cicli e dizionariSe usate un dizionario in un ciclo for, quest’ultimo attraversa le chiavi del dizionario. Per esempio, def stampa_isto(h):
for c in h:
print(c, h[c])
Ecco come risulta l’output: >>> h = istogramma('parrot')
>>> stampa_isto(h)
a 1
p 1
r 2
t 1
o 1
Di nuovo, le chiavi sono alla rinfusa. Per attraversare le chiavi disponendole in ordine, si può utilizzare la funzione predefinita sorted: >>> for chiave in sorted(h): ... print(chiave, h[chiave]) a 1 o 1 p 1 r 2 t 1 11.4 Lookup inversoDato un dizionario d e una chiave k, è facile trovare il valore corrispondente alla chiave: v = d[k]. Questa operazione è chiamata lookup. Ma se invece volete trovare la chiave k conoscendo il valore v? Avete due problemi: primo, ci possono essere più chiavi che corrispondono al valore v. A seconda dell’applicazione, potete riuscire a trovarne uno, oppure può essere necessario ricavare una lista che li contenga tutti. Secondo, non c’è una sintassi semplice per fare un lookup inverso; dovete impostare una ricerca. Ecco una funzione che richiede un valore e restituisce la prima chiave a cui corrisponde quel valore: def inverso_lookup(d, v):
for k in d:
if d[k] == v:
return k
raise LookupError()
Questa funzione è un altro esempio di schema di ricerca, ma usa un’istruzione che non abbiamo mai visto prima, raise. L’istruzione raise solleva un’eccezione; in questo caso genera un errore LookupError, che è un eccezione predefinita usata per indicare che un’operazione di lookup è fallita. Se arriviamo a fine ciclo, significa che v non compare nel dizionario come valore, per cui solleviamo un’eccezione. Ecco un esempio di lookup inverso riuscito: >>> h = istogramma('parrot')
>>> chiave = inverso_lookup(h, 2)
>>> chiave
'r'
E di uno fallito: >>> chiave = inverso_lookup(h, 3) Traceback (most recent call last): File "<stdin>", line 1, in ? File "<stdin>", line 5, in inverso_lookup LookupError Quando generate un errore, l’effetto è lo stesso di quando lo genera Python: viene stampato un traceback con un messaggio di errore. L’istruzione raise può ricevere come parametro opzionale un messaggio di errore dettagliato. Per esempio: >>> raise LookupError('il valore non compare nel dizionario')
Traceback (most recent call last):
File "<stdin>", line 1, in ?
LookupError: il valore non compare nel dizionario
Un lookup inverso è molto più lento di un lookup; se dovete farlo spesso, o se il dizionario diventa molto grande, le prestazioni del vostro programma potrebbero risentirne. 11.5 Dizionari e listeLe liste possono comparire come valori in un dizionario. Per esempio, se avete un dizionario che fa corrispondere le lettere alle loro frequenze, potreste volere l’inverso; cioè creare un dizionario che a partire dalle frequenze fa corrispondere le lettere. Poiché ci possono essere più lettere con la stessa frequenza, ogni valore del dizionario inverso dovrebbe essere una lista di lettere. Ecco una funzione che inverte un dizionario: def inverti_diz(d):
inverso = dict()
for chiave in d:
valore = d[chiave]
if valore not in inverso:
inverso[valore] = [chiave]
else:
inverso[valore].append(chiave)
return inverso
Per ogni ripetizione del ciclo, chiave prende una chiave da d e valore assume il corrispondente valore. Se valore non appartiene a inverso, vuol dire che non è ancora comparso, per cui creiamo un nuovo elemento e lo inizializziamo con un singleton (lista che contiene un solo elemento). Altrimenti, se il valore era già apparso, accodiamo la chiave corrispondente alla lista esistente. Ecco un esempio: >>> isto = istogramma('parrot')
>>> isto
{'a': 1, 'p': 1, 'r': 2, 't': 1, 'o': 1}
>>> inverso = inverti_diz(isto)
>>> inverso
{1: ['a', 'p', 't', 'o'], 2: ['r']}
La Figura 11.1 è un diagramma di stato che mostra isto e inverso. Un dizionario viene rappresentato come un riquadro con la scritta dict sopra e le coppie chiave-valore all’interno. Se i valori sono interi, float o stringhe, li raffiguro dentro il riquadro, lascio invece all’esterno le liste per mantenere semplice il diagramma. Le liste possono essere valori nel dizionario, come mostra questo esempio, ma non possono essere chiavi. Ecco cosa succede se ci provate: >>> t = [1, 2, 3] >>> d = dict() >>> d[t] = 'oops' Traceback (most recent call last): File "<stdin>", line 1, in ? TypeError: list objects are unhashable Ho accennato che i dizionari sono implementati usando una tabella hash, e questo implica che alle chiavi deve poter essere applicato un hash. Un hash è una funzione che prende un valore (di qualsiasi tipo) e restituisce un intero. I dizionari usano questi interi, chiamati valori hash, per conservare e consultare le coppie chiave-valore. Questo sistema funziona se le chiavi sono immutabili; ma se sono mutabili, come le liste, succedono disastri. Per esempio, nel creare una coppia chiave-valore, Python fa l’hashing della chiave e la immagazzina nello spazio corrispondente. Se modificate la chiave e quindi viene nuovamente calcolato l’hash, si collocherebbe in un altro spazio. In quel caso potreste avere due voci della stessa chiave, oppure non riuscire a trovare una chiave. In ogni caso il dizionario non funzionerà correttamente. Ecco perché le chiavi devono essere idonee all’hashing, e quelle mutabili come le liste non lo sono. Il modo più semplice per aggirare questo limite è usare le tuple, che vedremo nel prossimo capitolo. Dato che i dizionari sono mutabili, non possono essere usati come chiavi ma possono essere usati come valori. 11.6 MemoizzazioneSe vi siete sbizzarriti con la funzione fibonacci del Paragrafo 6.7, avrete notato che più grande è l’argomento che passate, maggiore è il tempo necessario per l’esecuzione della funzione. Inoltre, il tempo di elaborazione cresce rapidamente. Per capire il motivo, confrontate la Figura 11.2, che mostra il grafico di chiamata di fibonacci con n=4:
Un grafico di chiamata mostra l’insieme dei frame della funzione, con linee che collegano ciascun frame ai frame delle funzioni che chiama a sua volta. In cima al grafico, fibonacci con n=4 chiama fibonacci con n=3 e n=2. A sua volta, fibonacci con n=3 chiama fibonacci con n=2 e n=1. E così via. Provate a contare quante volte vengono chiamate fibonacci(0) e fibonacci(1). Questa è una soluzione inefficiente del problema, che peggiora ulteriormente al crescere dell’argomento. Una soluzione migliore è tenere da parte i valori che sono già stati calcolati, conservandoli in un dizionario. La tecnica di conservare per un uso successivo un valore già calcolato, così da non doverlo ricalcolare ogni volta, viene detta memoizzazione. Ecco una versione di fibonacci che usa la memoizzazione: memo = {0:0, 1:1}
def fibonacci(n):
if n in memo:
return memo[n]
res = fibonacci(n-1) + fibonacci(n-2)
memo[n] = res
return res
memo è un dizionario che conserva i numeri di Fibonacci già conosciuti. Parte con due elementi: 0 che corrisponde a 0, e 1 che corrisponde a 1. Ogni volta che fibonacci viene chiamata, controlla innanzitutto memo. Se quest’ultimo contiene già il risultato, ritorna immediatamente. Altrimenti deve calcolare il nuovo valore, lo aggiunge al dizionario e lo restituisce. Provate ad eseguire questa versione di fibonacci e a confrontarla con l’originale: troverete che è molto più veloce. 11.7 Variabili globaliNell’esempio precedente, memo viene creato esternamente alla funzione, pertanto appartiene al frame speciale chiamato Di frequente le variabili globali vengono usate come controlli o flag; vale a dire, variabili booleane che indicano quando una certa condizione è soddisfatta (True). Per esempio, alcuni programmi usano un flag di nome verbose per controllare che livello di dettaglio dare ad un output: verbose = True
def esempio1():
if verbose:
print('esempio1 in esecuzione')
Se cercate di riassegnare una variabile globale, potreste avere una sorpresa. L’esempio seguente vorrebbe controllare se una funzione è stata chiamata: stata_chiamata = False
def esempio2():
stata_chiamata = True # SBAGLIATO
Ma se la eseguite vedrete che il valore di Per riassegnare una variabile globale dall’interno di una funzione, dovete dichiarare la variabile globale prima di usarla: stata_chiamata = False
def esempio2():
global stata_chiamata
stata_chiamata = True
L’istruzione global dice all’interprete una cosa del genere: “In questa funzione, quando dico Ecco un altro esempio che cerca di aggiornare una variabile globale: conta = 0
def esempio3():
conta = conta + 1 # SBAGLIATO
UnboundLocalError: local variable 'conta' referenced before assignment Python presume che conta all’interno della funzione sia una variabile locale, e con questa premessa significa che state usando la variabile prima di averla inizializzata. La soluzione è ancora quella di dichiarare conta globale. def esempio3():
global conta
conta += 1
Se una variabile globale fa riferimento ad un valore mutabile, potete modificare il valore senza dichiarare la variabile: noto = {0:0, 1:1}
def esempio4():
noto[2] = 1
Pertanto, potete aggiungere, rimuovere e sostituire elementi di una lista o dizionario globali; tuttavia, se volete riassegnare la variabile, occorre dichiararla: def esempio5():
global noto
noto = dict()
Le variabili globali possono risultare utili, ma se ce ne sono molte e le modificate di frequente, possono rendere difficile il debug del programma. 11.8 DebugSe lavorate con banche dati di grosse dimensioni, può diventare oneroso fare il debug stampando e controllando i risultati di output manualmente. Ecco allora alcuni suggerimenti per fare il debug in queste situazioni:
Ancora, il tempo che impiegate a scrivere del codice temporaneo può essere ripagato dalla riduzione del tempo di debug. 11.9 Glossario
11.10 EserciziEsercizio 1
Scrivete una funzione che legga le parole in words.txt e le inserisca come chiavi in un dizionario. I valori non hanno importanza. Usate poi l’operatore in come modo rapido per controllare se una stringa è contenuta nel dizionario. Se avete svolto l’Esercizio 10, potete confrontare la velocità di questa implementazione con l’operatore in applicato alla lista e la ricerca binaria.
Esercizio 2
Leggete la documentazione del metodo dei dizionari setdefault
e usatelo per scrivere una versione più concisa di
Esercizio 3 Applicate la memoizzazione alla funzione di Ackermann dell’Esercizio 2 e provate a vedere se questa tecnica rende possibile il calcolo della funzione con argomenti più grandi. Suggerimento: no. Soluzione: http://thinkpython2.com/code/ackermann_memo.py.
Esercizio 4
Se avete svolto l’Esercizio 7, avete già una funzione di nome Usate un dizionario per scrivere una versione più rapida e semplice di
Esercizio 5
Due parole sono “ruotabili” se potete far ruotare le lettere dell’una per ottenere l’altra (vedere Scrivete un programma che legga un elenco di parole e trovi tutte le coppie di parole ruotabili. Soluzione: http://thinkpython2.com/code/rotate_pairs.py.
Esercizio 6
Ecco un altro quesito tratto da Car Talk (http://www.cartalk.com/content/puzzlers): “Questo ci è stato mandato da un amico di nome Dan O’Leary. Si è recentemente imbattuto in una parola inglese di una sillaba e cinque lettere che ha questa singolare proprietà: se togliete la prima lettera, le lettere restanti formano un omofono della prima parola, cioè un’altra parola che pronunciata suona allo stesso modo. Se poi rimettete la prima lettera e togliete la seconda, ottenete ancora un altro omofono della parola di origine. Qual è questa parola?” Potete usare il dizionario dell’Esercizio 1 per controllare se esiste una tale stringa nell’elenco di parole. Per controllare se due parole sono omofone, potete usare il CMU Pronouncing Dictionary, scaricabile da
http://www.speech.cs.cmu.edu/cgi-bin/cmudict oppure da
http://thinkpython2.com/code/c06d e potete anche procurarvi
http://thinkpython2.com/code/pronounce.py, che fornisce una funzione di nome Scrivete un programma che elenchi tutte le parole che risolvono il quesito. Soluzione: http://thinkpython2.com/code/homophone.py. |
ContributeIf you would like to make a contribution to support my books, you can use the button below. Thank you!
Are you using one of our books in a class?We'd like to know about it. Please consider filling out this short survey.
|