Estrazione dati
Scarica zip esercizi
Introduzione
In questo tutorial affronteremo il tema dell’estrazione di dati semi-strutturati, focalizzandoci in particolare sull’HTML. I file in questo formato seguono (o dovrebbero seguire !) le regole dell’XML, quindi guardando dei file HTML possiamo anche imparare qualcosa sul più generico XML.
Scaletta:
Impariamo due cose di HTML creando una paginetta web seguendo un semplice tutorial CoderDojoTrento (senza Python).
Chiedersi se vale la pena estrarre informazioni dall’HTML
Estrazione eventi del Trentino da visittrentino.info usando Python e BeautifulSoup 4
Per ogni evento, estrarremo nome, data, luogo, tipo, descrizione e li metteremo in una lista di dizionari Python così:
[{'data': '14/12/2017',
'descrizione': 'Al Passo Costalunga sfida tra i migliori specialisti del mondo',
'luogo': 'Passo Costalunga',
'nome': 'Coppa del Mondo di Snowboard',
'tipo': 'Sport, TOP EVENTI SPORT'},
{'data': '18/12/2017',
'descrizione': 'Lunedì 18 dicembre la Coppa Europa fa tappa in Val di Fassa',
'luogo': 'Pozza di Fassa',
'nome': 'Coppa Europa di sci alpino maschile - slalom speciale',
'tipo': 'Sport, TOP EVENTI SPORT'},
....
]
Infine scriveremo un file CSV
eventi.csvusando la lista di dizionari generata al punto precedente.
Che fare
Per avere un’idea di cosa sia l’HTML, prova a crearti una paginetta web seguendo il tutorial 1 di CoderDojoTrento (in questa parte non serve Python, puoi fare tutto online saltando la registrazione su Thimble)
Adesso puoi passare ad usare Python e Jupyter come al solito: scarica lo zip con esercizi e soluzioni
scompatta lo zip in una cartella, dovresti ottenere qualcosa del genere:
extraction
extraction.ipynb
extraction-sol.ipynb
jupman.py
ATTENZIONE: Per essere visualizzato correttamente, il file del notebook DEVE essere nella cartella szippata.
apri il Jupyter Notebook da quella cartella. Due cose dovrebbero aprirsi, prima una console e poi un browser. Il browser dovrebbe mostrare una lista di file: naviga la lista e apri il notebook
extraction.ipynbProsegui leggendo il file degli esercizi, ogni tanto al suo interno troverai delle scritte ESERCIZIO, che ti chiederanno di scrivere dei comandi Python nelle celle successive.
Scorciatoie da tastiera:
Per eseguire il codice Python dentro una cella di Jupyter, premi
Control+InvioPer eseguire il codice Python dentro una cella di Jupyter E selezionare la cella seguente, premi
Shift+InvioPer eseguire il codice Python dentro una cella di Jupyter E creare una nuova cella subito dopo, premi
Alt+InvioSe per caso il Notebook sembra inchiodato, prova a selezionare
Kernel -> Restart
1. Guardiamo l’html
Indipendentemente dalla domanda posta al punto precedente, per fini didattici proseguiremo con lo scraping html.
All’interno dello zip degli esercizi, c’è un file chiamato eventi.html. Dopo aver scompattato lo zip, apri il file nel tuo browser.
IMPORTANTE: usa solo il file eventi.html nella cartella del progetto Jupyter!
Il file eventi.html è stato salvato nel 2017 ed è un po’ più brutto da vedere della versione online sul sito di visttrentino (mancano immagini, etc). Se sei curioso di provare quella online, per vedere gli eventi come lista ricordati di cliccare sulla relativa icona:
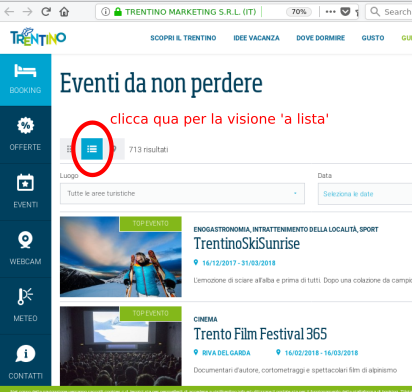
✪ 1.1 ESERCIZIO: Dopo aver aperto il file nel browser, visualizza l’HTML all’interno (premendo per es Ctrl+U in Firefox/Chrome/Safari). Familiarizzati un po’ con il file sorgente, cercando all’interno alcuni valori del primo evento , come per esempio il nome Coppa del Mondo di Snowboard, la data 14/12/2017, il luogo Passo Costalunga, il tipo Sport, TOP EVENTI SPORT, e la descrizione Al Passo Costalunga sfida tra i migliori specialisti del mondo.
NOTA 1: Per questo esercizio e tutti i seguenti, usa solo il file eventi.html indicato, NON usare l’html dalla versione live proveniente dalla di visittrentino, che può essere soggetta a cambiamenti !
NOTA 2: Evita di usare il browser Internet Explorer, in alternativa cerca di usare uno tra i seguenti (in quest’ordine): Firefox, Chrome, Safari.
Per maggiori informazioni sul formato XML, di cui l’HTML è una incarnazione, puoi consultare il libro Immersione in Python al capitolo 12,
2. Estrazione con BeautifulSoup
Installiamo le librerie beautifulsoup4 e il parser lxml:
Anaconda:
conda install beautifulsoup4conda install lxml
Linux/Mac (
--userinstalla nella propria home):python3 -m pip install --user beautifulsoup4python3 -m pip install --user lxml
I parser
Quanto installato sopra è quanto basta per questo esercizio. In particolare abbiamo installato il parser lxml, che è il componente che permette a BeautifulSoup di leggere l’HTML in modo veloce e lenient, cioè tollerando possibili errori di formattazione che potrebbero essere presenti nell’HTML (NOTA: la maggior parte dei documenti html nel mondo reale ha problemi di formattazione !). Prendendo pagine a caso da internet, lxml potrebbe non essere adatto. Se hai problemi a leggere pagine
html, potresti provare a sostituire lxml con html5lib, o altri parser. Per una lista di possibili parser, vedere la documentazione di BeautifulSoup
2.1 Estraiamo i nomi
✪ ESERCIZIO 2.1.1 Cerca nell’HTML la stringa Coppa del Mondo di Snowboard, cercando di capire bene in quali blocchi appare.
Cerchiamo con Python
Se hai fatto l’esercizio precedente, dovresti aver trovato vari blocchi che contengono Coppa del Mondo di Snowboard. Per un elenco e discussione, guarda la soluzione Per questo esercizio, considereremo principalmente i blocchi h4, in cui il nome Coppa del Mondo di Snowboard compare in questa riga:
<h4 class="moodboard__item-headline">Coppa del Mondo di Snowboard</h4>
vediamo cosa c’è intorno:
<div class="moodboard__item-text text-white">
<div>
<h4 class="moodboard__item-headline">Coppa del Mondo di Snowboard</h4>
<span class="moodboard__item-subline strong fz14 text-uppercase d-b">14/12/2017</span>
<span class="moodboard__item-subline strong fz14 d-b"><span class="icon icon-map-view fz20"></span> Passo Costalunga</span>
</div>
<div class="moodboard__item-text__link text-right">
<a href="https://www.visittrentino.info/it/guida/eventi/coppa-del-mondo-di-snowboard_e_165375" role="link"><span class="icon icon-circle-arrow fz30"></span></a>
</div>
</div>
Torniamo alla riga:
<h4 class="moodboard__item-headline">Coppa del Mondo di Snowboard</h4>
Notiamo che:
inizia con il tag
<h4>finisce simmetricamente con il tag di chiusura
</h4>il tag di apertura ha un parametro
class="moodboard__item-headline", ma al momento non ci interessaIl testo che cerchiamo
Coppa del Mondo di Snowboardè incluso tra i due tag
Per estrarre solo i nomi degli eventi dal documento, possiamo quindi cercare i tag h4. Eseguiamo la nostra prima estrazione in Python:
[1]:
# Importa l'oggetto BeatifulSoup dal modulo bs4:
from bs4 import BeautifulSoup
# apriamo il file degli eventi:
# - specifichiamo l'encoding come 'utf-8' ATTENZIONE: MAI DIMENTICARE L'ENCODING !!
# - lo chiamiamo con f, un nome che scegliamo noi
with open("eventi.html", encoding='utf-8') as f:
soup = BeautifulSoup(f, "lxml") # creiamo un oggetto che chiamiamo 'soup', usando il parser lxml
# soup ci permette di chiamare il metodo select, per selezionare per esempio solo tag 'h4':
# il metodo ritorna una lista di tag trovate nel documento. Per ogni tag ritornata, la stampiamo:
for tag in soup.select("h4"):
print(tag)
<h4 class="moodboard__item-headline">Coppa del Mondo di Snowboard</h4>
<h4 class="moodboard__item-headline">Coppa Europa di sci alpino maschile - slalom speciale</h4>
<h4 class="moodboard__item-headline">3Tre - AUDI FIS Ski World Cup</h4>
<h4 class="moodboard__item-headline">La Marcialonga di Fiemme e Fassa </h4>
<h4 class="moodboard__item-headline">TrentinoSkiSunrise: sulle piste alla luce dell’alba</h4>
<h4 class="moodboard__item-headline">Tour de Ski</h4>
<h4 class="moodboard__item-headline">La mia nuvola</h4>
<h4 class="moodboard__item-headline">Dormire sotto un cielo di stelle</h4>
<h4 class="moodboard__item-headline">Mercatini di Natale di Canale di Tenno e Rango </h4>
<h4 class="moodboard__item-headline">La Ciaspolada</h4>
<h4 class="moodboard__item-headline">Mercatini di Natale a Trento</h4>
<h4 class="moodboard__item-headline">Mercatini di Natale di Rovereto</h4>
<h4 class="moodboard__item-headline">Mercatino di Natale asburgico di Levico Terme</h4>
<h4 class="moodboard__item-headline">Magnifico Mercatino di Cavalese</h4>
<h4 class="moodboard__item-headline">Mercatino di Natale ad Arco</h4>
<h4 class="moodboard__item-headline">El paès dei presepi</h4>
Benissimo, abbiamo filtrato le tag coi nomi degli eventi. Ma noi vogliamo solo i nomi. Tipicamente dalle nostre tag ci interessa estrarre solo il testo. A tal fine. possiamo usare l’attributo text delle tag:
[2]:
for tag in soup.select("h4"):
print(tag.text)
Coppa del Mondo di Snowboard
Coppa Europa di sci alpino maschile - slalom speciale
3Tre - AUDI FIS Ski World Cup
La Marcialonga di Fiemme e Fassa
TrentinoSkiSunrise: sulle piste alla luce dell’alba
Tour de Ski
La mia nuvola
Dormire sotto un cielo di stelle
Mercatini di Natale di Canale di Tenno e Rango
La Ciaspolada
Mercatini di Natale a Trento
Mercatini di Natale di Rovereto
Mercatino di Natale asburgico di Levico Terme
Magnifico Mercatino di Cavalese
Mercatino di Natale ad Arco
El paès dei presepi
Casomai volessimo, si può anche estrarre un attributo, per esempio la class
[3]:
for tag in soup.select('h4'):
print(tag['class'])
['moodboard__item-headline']
['moodboard__item-headline']
['moodboard__item-headline']
['moodboard__item-headline']
['moodboard__item-headline']
['moodboard__item-headline']
['moodboard__item-headline']
['moodboard__item-headline']
['moodboard__item-headline']
['moodboard__item-headline']
['moodboard__item-headline']
['moodboard__item-headline']
['moodboard__item-headline']
['moodboard__item-headline']
['moodboard__item-headline']
['moodboard__item-headline']
La lista nomi
Intanto, cerchiamo di mettere tutti i nomi in una lista che chiameremo nomi
[4]:
nomi = []
for tag in soup.select("h4"):
nomi.append(tag.text)
[5]:
nomi
[5]:
['Coppa del Mondo di Snowboard',
'Coppa Europa di sci alpino maschile - slalom speciale',
'3Tre - AUDI FIS Ski World Cup',
'La Marcialonga di Fiemme e Fassa ',
'TrentinoSkiSunrise: sulle piste alla luce dell’alba',
'Tour de Ski',
'La mia nuvola',
'Dormire sotto un cielo di stelle',
'Mercatini di Natale di Canale di Tenno e Rango ',
'La Ciaspolada',
'Mercatini di Natale a Trento',
'Mercatini di Natale di Rovereto',
'Mercatino di Natale asburgico di Levico Terme',
'Magnifico Mercatino di Cavalese',
'Mercatino di Natale ad Arco',
'El paès dei presepi']
Una struttura dati per il CSV
Cominciamo a costruirci la struttura dati che modellerà il CSV che vogliamo creare. Un CSV può essere visto come una lista di dizionari. Ogni dizionario rappresenterà un evento. Passo passo, vorremmo arrivare ad avere una forma simile:
[{'data': '14/12/2017',
'descrizione': 'Al Passo Costalunga sfida tra i migliori specialisti del mondo',
'luogo': 'Passo Costalunga',
'nome': 'Coppa del Mondo di Snowboard',
'tipo': 'Sport, TOP EVENTI SPORT'},
{'data': '18/12/2017',
'descrizione': 'Lunedì 18 dicembre la Coppa Europa fa tappa in Val di Fassa',
'luogo': 'Pozza di Fassa',
'nome': 'Coppa Europa di sci alpino maschile - slalom speciale',
'tipo': 'Sport, TOP EVENTI SPORT'},
....
]
Inizializziamo la lista delle righe:
[6]:
righe = []
[7]:
righe
[7]:
[]
Dobbiamo aggiungere dei dizionari vuoti, ma quanti ce ne servono ? Vediamo quanti titoli abbiamo trovato con la funzione len:
[8]:
len(nomi)
[8]:
16
[9]:
for i in range(16):
righe.append({})
[10]:
righe
[10]:
[{}, {}, {}, {}, {}, {}, {}, {}, {}, {}, {}, {}, {}, {}, {}, {}]
Popoliamo i dizionari con i nomi
Adesso, in ogni dizionario, mettiamo un campo ‘nome’ usando il valore corrispendente trovato nella lista nomi:
[11]:
i = 0
for stringa in nomi:
righe[i]['nome'] = stringa # metti stringa nella riga i-esima, al campo 'nome' del dizionario
i += 1
Dovremmo cominciare a vedere i dizionari in righe popolati con i nomi. Verifichiamo:
[12]:
righe
[12]:
[{'nome': 'Coppa del Mondo di Snowboard'},
{'nome': 'Coppa Europa di sci alpino maschile - slalom speciale'},
{'nome': '3Tre - AUDI FIS Ski World Cup'},
{'nome': 'La Marcialonga di Fiemme e Fassa '},
{'nome': 'TrentinoSkiSunrise: sulle piste alla luce dell’alba'},
{'nome': 'Tour de Ski'},
{'nome': 'La mia nuvola'},
{'nome': 'Dormire sotto un cielo di stelle'},
{'nome': 'Mercatini di Natale di Canale di Tenno e Rango '},
{'nome': 'La Ciaspolada'},
{'nome': 'Mercatini di Natale a Trento'},
{'nome': 'Mercatini di Natale di Rovereto'},
{'nome': 'Mercatino di Natale asburgico di Levico Terme'},
{'nome': 'Magnifico Mercatino di Cavalese'},
{'nome': 'Mercatino di Natale ad Arco'},
{'nome': 'El paès dei presepi'}]
La funzione aggiungi_campo
Visto che i campi da aggiungere saranno diversi, definiamoci una funzione per aggiugere comodamente i campi alla variabile righe:
[13]:
# 'attributo' potrebbe essere la stringa 'nome'
# 'lista' potrebbe essere la lista dei nomi degli eventi ['Coppa del Mondo di Snowboard', 'Coppa Europa', ...]
def aggiungi_campo(attributo, lista):
i = 0
for stringa in lista:
righe[i][attributo] = stringa
i += 1
return righe # ritorniamo righe per stampare immediatamente il risultato in Jupyter
Chiamando aggiungi_campo con i nomi, non dovrebbe cambiare nulla perchè andremo semplicemente a riscrivere i campi nome dentro i dizionari della lista righe :
[14]:
aggiungi_campo('nome', nomi)
[14]:
[{'nome': 'Coppa del Mondo di Snowboard'},
{'nome': 'Coppa Europa di sci alpino maschile - slalom speciale'},
{'nome': '3Tre - AUDI FIS Ski World Cup'},
{'nome': 'La Marcialonga di Fiemme e Fassa '},
{'nome': 'TrentinoSkiSunrise: sulle piste alla luce dell’alba'},
{'nome': 'Tour de Ski'},
{'nome': 'La mia nuvola'},
{'nome': 'Dormire sotto un cielo di stelle'},
{'nome': 'Mercatini di Natale di Canale di Tenno e Rango '},
{'nome': 'La Ciaspolada'},
{'nome': 'Mercatini di Natale a Trento'},
{'nome': 'Mercatini di Natale di Rovereto'},
{'nome': 'Mercatino di Natale asburgico di Levico Terme'},
{'nome': 'Magnifico Mercatino di Cavalese'},
{'nome': 'Mercatino di Natale ad Arco'},
{'nome': 'El paès dei presepi'}]
2.2 Estraiamo le date
Bene, è tempo di aggiungere un altro campo, per esempio per la data. Dove trovarlo?
✪ DOMANDA 2.2.1: Cerca dentro l’HTML il valore della data della Coppa del Mondo di Snowboard 14/12/2017. Quanti valori trovi? Intorno alle date, trovi del testo che potrebbero permetterci di filtrare tutte e sole le date ?
✪ ESERCIZIO 2.2.2: Prova a filtrare qui sotto in Python le tag span, stampando i risultati. Trovi solo le date ?
[15]:
# scrivi qui il codice
Filtri più selettivi
Noi dobbiamo filtrare solo le tag span che contengono l’attributo class con un lungo valore criptico:
class="moodboard__item-subline strong fz14 text-uppercase d-b"
NOTA: Non farti spaventare da strani nomi che non conosci. Quando si traffica nei file HTML, si può trovare di tutto e bisogna ‘navigare a vista’. Per fortuna, spesso non occorre sapere troppi dettagli tecnici per estrarre testo rilevante.
Per estrarre le nostre date, possiamo sfruttare il fatto che alla funzione soup.select possiamo passare non solo tag ma qualunque espressione di selezione CSS
Tra le prime ne troviamo una che ci dice che possiamo scrivere l’attributo e il valore dentro a parentesi quadre dopo il nome della tag, come qua:
[16]:
for tag in soup.select('span[class="moodboard__item-subline strong fz14 text-uppercase d-b"]'):
print(tag.text)
14/12/2017
18/12/2017
22/12/2017
28/01/2018
06/01/2018 - 07/04/2018
06/01/2018 - 07/01/2018
01/10/2017 - 30/11/2017
31/10/2017 - 20/12/2017
19/11/2017 - 30/12/2017
06/01/2018
18/11/2017 - 06/01/2018
25/11/2017 - 06/01/2018
25/11/2017 - 06/01/2018
01/12/2017 - 06/01/2018
17/11/2017 - 07/01/2018
08/12/2017 - 07/01/2018
Ecco le nostre date! In questo caso particolare, il "moodboard__item-subline strong fz14 text-uppercase d-b" è così identificativo che non serve nemmeno specificare span:
[17]:
# nota che 'span' è rimosso:
for tag in soup.select('[class="moodboard__item-subline strong fz14 text-uppercase d-b"]'):
print(tag.text)
14/12/2017
18/12/2017
22/12/2017
28/01/2018
06/01/2018 - 07/04/2018
06/01/2018 - 07/01/2018
01/10/2017 - 30/11/2017
31/10/2017 - 20/12/2017
19/11/2017 - 30/12/2017
06/01/2018
18/11/2017 - 06/01/2018
25/11/2017 - 06/01/2018
25/11/2017 - 06/01/2018
01/12/2017 - 06/01/2018
17/11/2017 - 07/01/2018
08/12/2017 - 07/01/2018
✪ DOMANDA 2.2.3: possiamo scrivere direttamente senza nient’altro la stringa moodboard__item-subline strong fz14 text-uppercase d-b nella select ? Scrivi qui sotto i tuoi esperimenti.
[18]:
# scrivi qui
Come fatto prima, possiamo crearci una lista per le date:
[19]:
date_eventi = []
for tag in soup.select('[class="moodboard__item-subline strong fz14 text-uppercase d-b"]'):
date_eventi.append(tag.text)
[20]:
date_eventi
[20]:
['14/12/2017',
'18/12/2017',
'22/12/2017',
'28/01/2018',
'06/01/2018 - 07/04/2018',
'06/01/2018 - 07/01/2018',
'01/10/2017 - 30/11/2017',
'31/10/2017 - 20/12/2017',
'19/11/2017 - 30/12/2017',
'06/01/2018',
'18/11/2017 - 06/01/2018',
'25/11/2017 - 06/01/2018',
'25/11/2017 - 06/01/2018',
'01/12/2017 - 06/01/2018',
'17/11/2017 - 07/01/2018',
'08/12/2017 - 07/01/2018']
Per sincerarci di aver rastrellato tutte le date necessarie, possiamo controllare quante sono:
[21]:
len(date_eventi)
[21]:
16
Adesso possiamo sfruttare la funzione di prima aggiungi_campo per aggiornare righe:
[22]:
aggiungi_campo('data', date_eventi)
[22]:
[{'nome': 'Coppa del Mondo di Snowboard', 'data': '14/12/2017'},
{'nome': 'Coppa Europa di sci alpino maschile - slalom speciale',
'data': '18/12/2017'},
{'nome': '3Tre - AUDI FIS Ski World Cup', 'data': '22/12/2017'},
{'nome': 'La Marcialonga di Fiemme e Fassa ', 'data': '28/01/2018'},
{'nome': 'TrentinoSkiSunrise: sulle piste alla luce dell’alba',
'data': '06/01/2018 - 07/04/2018'},
{'nome': 'Tour de Ski', 'data': '06/01/2018 - 07/01/2018'},
{'nome': 'La mia nuvola', 'data': '01/10/2017 - 30/11/2017'},
{'nome': 'Dormire sotto un cielo di stelle',
'data': '31/10/2017 - 20/12/2017'},
{'nome': 'Mercatini di Natale di Canale di Tenno e Rango ',
'data': '19/11/2017 - 30/12/2017'},
{'nome': 'La Ciaspolada', 'data': '06/01/2018'},
{'nome': 'Mercatini di Natale a Trento', 'data': '18/11/2017 - 06/01/2018'},
{'nome': 'Mercatini di Natale di Rovereto',
'data': '25/11/2017 - 06/01/2018'},
{'nome': 'Mercatino di Natale asburgico di Levico Terme',
'data': '25/11/2017 - 06/01/2018'},
{'nome': 'Magnifico Mercatino di Cavalese',
'data': '01/12/2017 - 06/01/2018'},
{'nome': 'Mercatino di Natale ad Arco', 'data': '17/11/2017 - 07/01/2018'},
{'nome': 'El paès dei presepi', 'data': '08/12/2017 - 07/01/2018'}]
2.3 Estraiamo i luoghi
E’ tempo di aggiungere il luogo.
✪✪ ESERCIZIO 2.3.1: Cerca nell’HTML il luogo Passo Costalunga dell’evento Coppa di Snowboard. Con quale criterio possiamo filtrare i luoghi ?
✪ ESERCIZIO 2.3.2: Scrivi il codice Python per estrarre i luoghi e metterlo nella lista luoghi (usa sempre l’html intorno ai blocchi h4)
SUGGERIMENTO: Non importa se il testo che cerchi è contenuto in uno span all’interno di un’altro span identificabile
Mostra soluzione[23]:
# scrivi qui
Passo Costalunga
Pozza di Fassa
Madonna di Campiglio
Val di Fassa
Tesero
Pozza di Fassa
Pozza di Fassa
Tenno
Fondo
Trento
Rovereto
Levico Terme
Cavalese
Arco
Baselga di Piné
[23]:
[' Passo Costalunga',
' Pozza di Fassa',
' Madonna di Campiglio',
' Val di Fassa ',
' Tesero',
' Pozza di Fassa',
' Pozza di Fassa',
' Tenno',
' Fondo',
' Trento',
' Rovereto',
' Levico Terme',
' Cavalese',
' Arco',
' Baselga di Piné']
2.3 Sistemiamo i luoghi
✪ DOMANDA 2.3.3: Quanti luoghi hai trovato ? Dovrebbero essere 16, ma se ne hai trovato 15 allora manca un dato! Che dato è? Guarda la pagina e cerca se qualche evento non ha un luogo. In che posizione è nella lista ?
Mostra risposta✪ ESERCIZIO 2.3.4: Come rimediare al problema? Ci sono metodo più furbi, ma per stavolta semplicemente possiamo inserire una stringa vuota alla posizione della lista luoghi in cui ci dovrebbe essere il campo mancante - e cioè dopo Val di Fassa. Per farlo, puoi usare il metodo insert. Qua puoi vedere qualche esempio di utilizzo.
NOTA: Ricordati che gli indici iniziano da 0 !
[24]:
prova = ['a','b','c','d']
prova.insert(0, 'x') # inserisce 'x' all'inizio in posizione 0
prova
[24]:
['x', 'a', 'b', 'c', 'd']
[25]:
prova = ['a','b','c','d']
prova.insert(2, 'x') # inserisce 'x' a metà
prova
[25]:
['a', 'b', 'x', 'c', 'd']
[26]:
# scrivi qui la soluzione
[26]:
[' Passo Costalunga',
' Pozza di Fassa',
' Madonna di Campiglio',
' Val di Fassa ',
'',
' Tesero',
' Pozza di Fassa',
' Pozza di Fassa',
' Tenno',
' Fondo',
' Trento',
' Rovereto',
' Levico Terme',
' Cavalese',
' Arco',
' Baselga di Piné']
✪✪ ESERCIZIO 2.3.5: Prima di procedere, verifica che la lunghezza della lista len(luoghi) sia corretta (= 16). Adesso, osserva attentamente le stringhe dei luoghi. Dovresti vedere che iniziano tutte con uno spazio inutile: sistema la lista luoghi togliendo gli spazi extra usando una list comprehension (vedere Capitolo 19.2 Pensare in Python). Per eliminare gli spazi puoi usare il metodo delle
stringhe .strip()
NOTA: quando crei una list comprehension, ne generi una nuova, la lista originale non viene modificata!
Mostra soluzione[27]:
# scrivi qui
2.4 Tipo dell’evento
Proseguiamo con il tipo dell’evento. Per esempio, per la Coppa del Mondo di Snowboard, la tipologia dell’evento sarebbe Sport, TOP EVENTI SPORT
✪ ESERCIZIO 2.4.1: Cerca la stringa Sport, TOP EVENTI SPORT nell’HTML. Quante occorrenze ci sono ? E’ possibile filtrare il tipo eventi in modo univoco ?
✪✪ ESERCIZIO 2.4.2: Scrivi il codice Python per estrarre la lista degli eventi, e chiamala tipo_evento. Per farlo, puoi usare il codice già visto in precedenza, ma questa volta, per creare la lista sforzati di usare una list comprehension. Verifica poi che la lunghezza della stringa sia 16.
SUGGERIMENTO: La lista originale da cui prelevare il testo delle le tag sarà creata dalla chiamata a soup.select
[28]:
# scrivi qui
Sport, TOP EVENTI SPORT
Sport, TOP EVENTI SPORT
Sport, TOP EVENTI SPORT
Sport, TOP EVENTI SPORT
Enogastronomia, Intrattenimento della Località, Sport
Sport, Intrattenimento della Località, Enogastronomia
Wellness
Wellness
Intrattenimento della Località, Mercati e mercatini
Sport, TOP EVENTI SPORT
Intrattenimento della Località, Mercati e mercatini
Intrattenimento della Località, Mercati e mercatini
Mercati e mercatini, Intrattenimento della Località
Intrattenimento della Località, Mercati e mercatini
Intrattenimento della Località, Mercati e mercatini
Mercati e mercatini, Folklore
[28]:
['Sport, TOP EVENTI SPORT',
'Sport, TOP EVENTI SPORT',
'Sport, TOP EVENTI SPORT',
'Sport, TOP EVENTI SPORT',
'Enogastronomia, Intrattenimento della Località, Sport',
'Sport, Intrattenimento della Località, Enogastronomia',
'Wellness',
'Wellness',
'Intrattenimento della Località, Mercati e mercatini',
'Sport, TOP EVENTI SPORT',
'Intrattenimento della Località, Mercati e mercatini',
'Intrattenimento della Località, Mercati e mercatini',
'Mercati e mercatini, Intrattenimento della Località',
'Intrattenimento della Località, Mercati e mercatini',
'Intrattenimento della Località, Mercati e mercatini',
'Mercati e mercatini, Folklore']
2.5 descrizione
Rimane da aggiungere la descrizione, per esempio per la Coppa del Mondo di Snowboard la descrizione sarebbe “Al Passo Costalunga sfida tra i migliori specialisti del mondo”.
✪ ESERCIZIO 2.5.1: Cerca manualmente nell’HTML la stringa Al Passo Costalunga sfida tra i migliori specialisti del mondo. In quante posizioni appare ? In base a quali criteri potremo filtrare i tipi degli eventi ? NOTA: In base a quanto sai finora, ti sarà impossibile trovare un selettore che possa filtrare quello che serve, quindi per ora pensa solo a trovare stringhe ricorrenti intorno alle descrizioni
Trovare la descrizione in Python
Guarda la soluzione dell’esercizio precedente. Troverai scritto che la tag <ul class="list-unstyled list-inline list__teaser__list mb15 mt10"> contiene una classe, se la cerchiamo nel documento scopriremo che tutte queste ul con questa classe compaiono sempre e solo prima del <p> con le descrizioni che vogliamo noi. Non ci resta quindi che trovare un selettore CSS che
trovi le tag
ulconclass=list-unstyled list-inline list__teaser__list mb15 mt10selezioni la tag successiva
p
Per fare ciò possiamo usare il selettore col simbolo +, quindi nella select basterà scrivere:
[29]:
soup.select('ul[class="list-unstyled list-inline list__teaser__list mb15 mt10"] + p')
[29]:
[<p>Al Passo Costalunga sfida tra i migliori specialisti del mondo</p>,
<p>Lunedì 18 dicembre la Coppa Europa fa tappa in Val di Fassa</p>,
<p>Torna il mitico slalom in notturna: vivi l'evento da VIP!</p>,
<p>La “regina” delle granfondo compie 45 anni</p>,
<p>L'emozione di sciare all’alba e prima di tutti. Dopo, una colazione da campioni!</p>,
<p>Coppa del Mondo Sci di Fondo
</p>,
<p>Contest fotografico della Nuvola del Benessere</p>,
<p>Fra le nuvole ai piedi delle Dolomiti</p>,
<p>L'incanto genuino del Natale</p>,
<p>La regina delle ciaspole nel giorno della Befana</p>,
<p>Profumi, luci, atmosfera di festa </p>,
<p>La forza della tradizione con un omaggio all'arte</p>,
<p>Parco secolare degli Asburgo </p>,
<p>Musica, zelten, vin brulé e spumante Trentodoc per assaporare l’atmosfera prenatalizia</p>,
<p>Quasi 40 casette negli angoli più suggestivi del centro</p>,
<p>Tradizioni e mercatini natalizi di Pinè</p>]
Benissimo, abbiamo ottenuto la lista dei <p> che vogliamo. Adesso possiamo mettere il testo interno dei <p> dentro una lista che chiameremo descrizioni. Possiamo farlo in un colpo solo usando una list comprehension:
[30]:
descrizioni = [tag.text for tag in soup.select('ul[class="list-unstyled list-inline list__teaser__list mb15 mt10"] + p')]
[31]:
descrizioni
[31]:
['Al Passo Costalunga sfida tra i migliori specialisti del mondo',
'Lunedì 18 dicembre la Coppa Europa fa tappa in Val di Fassa',
"Torna il mitico slalom in notturna: vivi l'evento da VIP!",
'La “regina” delle granfondo compie 45 anni',
"L'emozione di sciare all’alba e prima di tutti. Dopo, una colazione da campioni!",
'Coppa del Mondo Sci di Fondo\n',
'Contest fotografico della Nuvola del Benessere',
'Fra le nuvole ai piedi delle Dolomiti',
"L'incanto genuino del Natale",
'La regina delle ciaspole nel giorno della Befana',
'Profumi, luci, atmosfera di festa ',
"La forza della tradizione con un omaggio all'arte",
'Parco secolare degli Asburgo ',
'Musica, zelten, vin brulé e spumante Trentodoc per assaporare l’atmosfera prenatalizia',
'Quasi 40 casette negli angoli più suggestivi del centro',
'Tradizioni e mercatini natalizi di Pinè']
Come al solito, verifichiamo che la lista delle descrizioni sia di 16 elementi:
[32]:
len(descrizioni)
[32]:
16
2.6 Riempiamo la variabile righe
Ricapitolando tutto quanto visto precedentemente, popoliamo righe con i dizionari e tutti i campi per assicurarci di avere la struttura dati corretta. In questa riscrittura, usiamo di più le list comprehnesion per avere codice più sintetico:
[33]:
righe = []
for i in range(len(soup.select("h4"))):
righe.append({})
aggiungi_campo('nome', [tag.text for tag in soup.select("h4")])
aggiungi_campo('data', [tag.text for tag in soup.select('[class="moodboard__item-subline strong fz14 text-uppercase d-b"]')])
luoghi = [tag.text.strip() for tag in soup.select('[class="moodboard__item-subline strong fz14 d-b"]')]
luoghi.insert(4, '')
aggiungi_campo('luogo', luoghi)
aggiungi_campo('tipo', [tag.text for tag in soup.select('[class="text-secondary fz14 text-uppercase strong"]')])
aggiungi_campo('descrizione',
[tag.text for tag in soup.select('ul[class="list-unstyled list-inline list__teaser__list mb15 mt10"] + p')])
[33]:
[{'nome': 'Coppa del Mondo di Snowboard',
'data': '14/12/2017',
'luogo': 'Passo Costalunga',
'tipo': 'Sport, TOP EVENTI SPORT',
'descrizione': 'Al Passo Costalunga sfida tra i migliori specialisti del mondo'},
{'nome': 'Coppa Europa di sci alpino maschile - slalom speciale',
'data': '18/12/2017',
'luogo': 'Pozza di Fassa',
'tipo': 'Sport, TOP EVENTI SPORT',
'descrizione': 'Lunedì 18 dicembre la Coppa Europa fa tappa in Val di Fassa'},
{'nome': '3Tre - AUDI FIS Ski World Cup',
'data': '22/12/2017',
'luogo': 'Madonna di Campiglio',
'tipo': 'Sport, TOP EVENTI SPORT',
'descrizione': "Torna il mitico slalom in notturna: vivi l'evento da VIP!"},
{'nome': 'La Marcialonga di Fiemme e Fassa ',
'data': '28/01/2018',
'luogo': 'Val di Fassa',
'tipo': 'Sport, TOP EVENTI SPORT',
'descrizione': 'La “regina” delle granfondo compie 45 anni'},
{'nome': 'TrentinoSkiSunrise: sulle piste alla luce dell’alba',
'data': '06/01/2018 - 07/04/2018',
'luogo': '',
'tipo': 'Enogastronomia, Intrattenimento della Località, Sport',
'descrizione': "L'emozione di sciare all’alba e prima di tutti. Dopo, una colazione da campioni!"},
{'nome': 'Tour de Ski',
'data': '06/01/2018 - 07/01/2018',
'luogo': 'Tesero',
'tipo': 'Sport, Intrattenimento della Località, Enogastronomia',
'descrizione': 'Coppa del Mondo Sci di Fondo\n'},
{'nome': 'La mia nuvola',
'data': '01/10/2017 - 30/11/2017',
'luogo': 'Pozza di Fassa',
'tipo': 'Wellness',
'descrizione': 'Contest fotografico della Nuvola del Benessere'},
{'nome': 'Dormire sotto un cielo di stelle',
'data': '31/10/2017 - 20/12/2017',
'luogo': 'Pozza di Fassa',
'tipo': 'Wellness',
'descrizione': 'Fra le nuvole ai piedi delle Dolomiti'},
{'nome': 'Mercatini di Natale di Canale di Tenno e Rango ',
'data': '19/11/2017 - 30/12/2017',
'luogo': 'Tenno',
'tipo': 'Intrattenimento della Località, Mercati e mercatini',
'descrizione': "L'incanto genuino del Natale"},
{'nome': 'La Ciaspolada',
'data': '06/01/2018',
'luogo': 'Fondo',
'tipo': 'Sport, TOP EVENTI SPORT',
'descrizione': 'La regina delle ciaspole nel giorno della Befana'},
{'nome': 'Mercatini di Natale a Trento',
'data': '18/11/2017 - 06/01/2018',
'luogo': 'Trento',
'tipo': 'Intrattenimento della Località, Mercati e mercatini',
'descrizione': 'Profumi, luci, atmosfera di festa '},
{'nome': 'Mercatini di Natale di Rovereto',
'data': '25/11/2017 - 06/01/2018',
'luogo': 'Rovereto',
'tipo': 'Intrattenimento della Località, Mercati e mercatini',
'descrizione': "La forza della tradizione con un omaggio all'arte"},
{'nome': 'Mercatino di Natale asburgico di Levico Terme',
'data': '25/11/2017 - 06/01/2018',
'luogo': 'Levico Terme',
'tipo': 'Mercati e mercatini, Intrattenimento della Località',
'descrizione': 'Parco secolare degli Asburgo '},
{'nome': 'Magnifico Mercatino di Cavalese',
'data': '01/12/2017 - 06/01/2018',
'luogo': 'Cavalese',
'tipo': 'Intrattenimento della Località, Mercati e mercatini',
'descrizione': 'Musica, zelten, vin brulé e spumante Trentodoc per assaporare l’atmosfera prenatalizia'},
{'nome': 'Mercatino di Natale ad Arco',
'data': '17/11/2017 - 07/01/2018',
'luogo': 'Arco',
'tipo': 'Intrattenimento della Località, Mercati e mercatini',
'descrizione': 'Quasi 40 casette negli angoli più suggestivi del centro'},
{'nome': 'El paès dei presepi',
'data': '08/12/2017 - 07/01/2018',
'luogo': 'Baselga di Piné',
'tipo': 'Mercati e mercatini, Folklore',
'descrizione': 'Tradizioni e mercatini natalizi di Pinè'}]
3. Scriviamo il CSV
✪✪ ESERCIZIO 3.1: Prova a scrivere un file CSV contenente tutti i dati raccolti, con quest’ordine di colonne:
nome, data, luogo, tipo, descrizione
Diversamente da quanto fatto finora, in cui abbiamo solo considerato righe come liste, in questo caso dato che abbiamo dizionari ci servirà un oggetto di tipo DictWriter. Leggi la documentazione Python su DictWriter e copiandone l’esempio prova a scrivere il csv in un file chiamato eventi.csv.
NOTA: Per testare il tutto, fai attenzione a che nella cartella di questo progetto non sia già presente il file eventi.csv, in caso eliminalo a mano.
[34]:
# scrivi qui
✪✪✪ ESERCIZIO 3.2: Abbiamo dei luoghi estratti dall’HTML. Nella lezione sull’integrazione dati, abbiamo imparato a usare Webapi di MapQuest per ottenere delle coordinate geografiche a partire da nomi di luoghi. Riusciresti quindi a:
usare la libreria
requestse webapi MapQuest per arricchire prima i dizionari dirigheconlatelonaggiungere
latelonal CSV generatoCaricare il CSV in Umap
[35]:
# scrivi qui