Information retrieval
Scarica zip esercizi
ATTENZIONE: tutorial in progress !
Questo tutorial è pensato per dare un’idea rapida dei problemi principali dell’information retrieval ma è ancora incompleto e spesso presenta i concetti in modo molto semplificato. Se l’argomento t’appassiona non mancano buoni libri sul tema!
L’ Information retrieval è l’attività che svolgono i sistemi informatici quando devono recuperare rapidamente delle informazioni rilevanti . Perchè questi due aggettivi?
Al giorno d’oggi molte aziende hanno a che fare con una mole di dati rilevante - i famosi big data. Sia i giganti dell’Information Technology (IT) come Google e Amazon che aziende di dimensioni più modeste per varie ragioni devono fornire ai clienti dei sistemi di ricerca efficienti. Nel caso di Google i clienti vogliono trovare tutte le pagine nel web che contengono un certo testo. Per Amazon, il cliente desidera conoscere tutti i prodotti in una certa categoria, o prodotti simili ad uno già cercato.
Che fare
scompatta lo zip in una cartella, dovresti ottenere qualcosa del genere:
information-retrieval
information-retrieval.ipynb
information-retrieval-sol.ipynb
jupman.py
ATTENZIONE: Per essere visualizzato correttamente, il file del notebook DEVE essere nella cartella szippata.
apri il Jupyter Notebook da quella cartella. Due cose dovrebbero aprirsi, prima una console e poi un browser. Il browser dovrebbe mostrare una lista di file: naviga la lista e apri il notebook
information-retrieval.ipynbProsegui leggendo il file degli esercizi, ogni tanto al suo interno troverai delle scritte ESERCIZIO, che ti chiederanno di scrivere dei comandi Python nelle celle successive.
Scorciatoie da tastiera:
Per eseguire il codice Python dentro una cella di Jupyter, premi
Control+InvioPer eseguire il codice Python dentro una cella di Jupyter E selezionare la cella seguente, premi
Shift+InvioPer eseguire il codice Python dentro una cella di Jupyter E creare una nuova cella subito dopo, premi
Alt+InvioSe per caso il Notebook sembra inchiodato, prova a selezionare
Kernel -> Restart
Costruiamo il nostro motore di ricerca
Consideriamo in particolare il problema che risolvono i motori di ricerca come Google.
Supponiamo di avere tante pagine web (tutto il web !): per ogni pagina abbiamo l’indirizzo della pagina (come https://it.softpython.org ) e il testo che contiene in formato HTML, per esempio:
<h2>Presentazione</h2>
<p>Il corso SoftPython fornisce un’introduzione al processamento dati usando Python, un linguaggio di programmazione popolare sia nell’industria che nell’ambito della ricerca. Fra le varie cose tratteremo Matplotlib.</p>
Se hai guardato il tutorial sull’estrazione dati dovresti già avere un’idea di cosa è l’HTML. Se non l’hai fatto niente paura: puoi tranquillamente ignorare le strane sequenze racchiuse tra minore e maggiore come <h2>, tieni solo presente che si chiamano tag HTML. Parlando in genere, le useremo come esempio del fatto che quando si cerca dentro del testo si possono trovare cose strane o indesiderate, e un sistema di ricerca
fatto bene deve essere pronto alle sorprese.
L’utente vuole trovare tutte le pagine contenti un certo testo, per esempio sul sito di SoftPython potrebbe voler cercare dove ci sono spiegazioni su grafici con matplotlib
INPUT: stringa di ricerca (per es:
grafici con matplotlibOUTPUT: tutte le pagine che contengono la stringa (in questo caso
grafici con matplotlib
Se hai seguito qualcuno dei tutorial sul nostro sito, forse ti potrebbe venire in mente già una o due soluzioni a questo problema.
DOMANDA: Prima di proseguire, pensa a
come rappresenteresti i dati delle pagine in Python?
che funzione Python definiresti per fare la ricerca?
quali sarebbero i parametri della funzione?
cosa varia ad ogni chiamata e cosa invece è più ‘statico’ ?
Non ti preoccupare delle performance - quando si progetta un algoritmo all’inizio conviene capire bene cosa si vuole. Solo dopo aver realizzato un prototipo e nel caso sia troppo lento, ci si comincia a preoccupare delle performance !
Una prima soluzione
Vediamone qua una possibile soluzione al problema.
Rappresentare una pagina
Cominciamo a rappresentare le pagine web. Per farlo, possiamo usare un semplice dizionario con le chiavi url (l’indirizzo web) e contenuto per il testo:
{
'url': 'http://it.softpython.org',
'contenuto' : '<h2>Presentazione</h2><p>Il corso SoftPython fornisce un’introduzione al processamento dati usando Python, un linguaggio di programmazione popolare sia nell’industria che nell’ambito della ricerca. Fra le varie cose tratteremo Matplotlib.</p>'
}
Un database per le pagine
Il web ha tante pagine, quindi vorremo mettere la collezione di pagine in un contenitore. Ai fini dell’esempio proviamo ad usare una lista. La popoleremo con due pagine, quella principale e la pagina chiamata Visualizzazione. Infine assegnamo la lista alla variabile pagine (ricordiamo che il testo che mettiamo è semplificato rispetto a quello effettivo che trovate sul sito)
[1]:
pagine = [
{
'url': 'https://it.softpython.org',
'contenuto' : '<h2>Presentazione</h2><p>Il corso SoftPython fornisce un’introduzione al processamento dati usando Python, un linguaggio di programmazione popolare sia nell’industria che nell’ambito della ricerca. Fra le varie cose tratteremo Matplotlib.</p>'
},
{
'url': 'https://it.softpython.org/visualization/visualization-sol.html',
'contenuto' : '<h2>Visualizzazione</h2> <p>Excel ci permette di creare molti tipi di visualizzazione ma a volte è limitato, perciò useremo Python facendo grafici in Matplotlib. Matplotlib è una libreria eccezionale che consente di creare qualunque visualizzazione desideriamo. Procediamo dunque a importare matplotlib in Python:</p>'
}
]
Supponiamo che tutto il web sia costituito dalle due pagine precedenti. Supponiamo anche che le pagine non cambino mai nel tempo. Abbiamo creato il nostro primo rudimentale database del web!
Implementiamo la funzione di ricerca
Ma come possiamo implementare la ricerca?
[2]:
def ricerca(stringa):
risultati = [] # all'inizio non sappiamo quali pagine contengono le parole cercate
for pagina in pagine: # scorri le pagine
if stringa in pagina['contenuto']: # se la stringa cercata è nel contenuto della pagina ...
risultati.append(pagina) # aggiungi la pagina ai risultati collezionati finora
return risultati # ritorna le pagine collezionate finora
Proviamola con una sola parola chiave grafici, dovrebbe ritornarci la pagina 1-esima sulla visualizzazione:
[3]:
ricerca("grafici")
[3]:
[{'url': 'https://it.softpython.org/visualization/visualization-sol.html',
'contenuto': '<h2>Visualizzazione</h2> <p>Excel ci permette di creare molti tipi di visualizzazione ma a volte è limitato, perciò useremo Python facendo grafici in Matplotlib. Matplotlib è una libreria eccezionale che consente di creare qualunque visualizzazione desideriamo. Procediamo dunque a importare matplotlib in Python:</p>'}]
Funziona ! Baldanzosi col risultato del nostro primo esperimento, proviamo a cerca la stringa completa che ci eravamo prefissati all’inizio, grafici con matplotlib:
[4]:
ricerca("grafici con matplotlib")
[4]:
[]
Nulla ! Come mai?
DOMANDA: Prima di proseguire, osserva bene il testo semplificato della pagina Visualizzazione e prova a dare una risposta. Ci sono due problemi principali. Quali sono?
Mostra rispostaDOMANDA: Come risolveresti i problemi qua sopra?
Mostra rispostaUna ricerca più efficace
Accediamo al contenuto della prima pagina:
[5]:
pagine[0]["contenuto"]
[5]:
'<h2>Presentazione</h2><p>Il corso SoftPython fornisce un’introduzione al processamento dati usando Python, un linguaggio di programmazione popolare sia nell’industria che nell’ambito della ricerca. Fra le varie cose tratteremo Matplotlib.</p>'
Se cerco "matplotlib" in maiuscolo non lo troverò:
[6]:
"matplotlib" in pagine[0]["contenuto"]
[6]:
False
ma se metto tutto in minuscolo:
ATTENZIONE: lower(), come tutti i metodi delle stringhe, ritorna una nuova stringa e non modifica l’originale !!
[7]:
pagine[0]["contenuto"].lower()
[7]:
'<h2>presentazione</h2><p>il corso softpython fornisce un’introduzione al processamento dati usando python, un linguaggio di programmazione popolare sia nell’industria che nell’ambito della ricerca. fra le varie cose tratteremo matplotlib.</p>'
adesso, matplotlib in minuscolo verrà trovato nella stringa generata dall’espressione qua sopra:
[8]:
"matplotlib" in pagine[0]["contenuto"].lower()
[8]:
True
Per essere sempre sicuri di trovare quello che l’utente cerca, conviene chiamare .lower() anche sulla stringa dell’utente:
[9]:
"matplotlib".lower() in pagine[0]["contenuto"].lower()
[9]:
True
[10]:
"Matplotlib".lower() in pagine[0]["contenuto"].lower()
[10]:
True
Proviamo a scrivere una ricerca più furba ricerca2 che applica quanto visto sopra:
[11]:
def ricerca2(stringa):
risultati = []
for pagina in pagine:
if stringa.lower() in pagina['contenuto'].lower():
risultati.append(pagina)
return risultati
[12]:
ricerca2("matplotlib")
[12]:
[{'url': 'https://it.softpython.org',
'contenuto': '<h2>Presentazione</h2><p>Il corso SoftPython fornisce un’introduzione al processamento dati usando Python, un linguaggio di programmazione popolare sia nell’industria che nell’ambito della ricerca. Fra le varie cose tratteremo Matplotlib.</p>'},
{'url': 'https://it.softpython.org/visualization/visualization-sol.html',
'contenuto': '<h2>Visualizzazione</h2> <p>Excel ci permette di creare molti tipi di visualizzazione ma a volte è limitato, perciò useremo Python facendo grafici in Matplotlib. Matplotlib è una libreria eccezionale che consente di creare qualunque visualizzazione desideriamo. Procediamo dunque a importare matplotlib in Python:</p>'}]
[13]:
ricerca2("Matplotlib")
[13]:
[{'url': 'https://it.softpython.org',
'contenuto': '<h2>Presentazione</h2><p>Il corso SoftPython fornisce un’introduzione al processamento dati usando Python, un linguaggio di programmazione popolare sia nell’industria che nell’ambito della ricerca. Fra le varie cose tratteremo Matplotlib.</p>'},
{'url': 'https://it.softpython.org/visualization/visualization-sol.html',
'contenuto': '<h2>Visualizzazione</h2> <p>Excel ci permette di creare molti tipi di visualizzazione ma a volte è limitato, perciò useremo Python facendo grafici in Matplotlib. Matplotlib è una libreria eccezionale che consente di creare qualunque visualizzazione desideriamo. Procediamo dunque a importare matplotlib in Python:</p>'}]
Performance
DOMANDA:
Se abbiamo miliardi di pagine, conviene cercarle in una lista? Se la stringa che cerchiamo sta nell’ultima pagina, l’algoritmo di ricerca quante pagine guarda prima di trovare quella d’interesse?
Che strutture dati alternative potremmo usare per la ricerca?
Ordinamento
Osserva di nuovo bene il testo delle pagine. Noti delle particolarità / differenze tra le due pagine ?
[14]:
pagine = [
{
'url': 'http://it.softpython.org',
'contenuto' : '<h2>Presentazione</h2><p>Il corso SoftPython fornisce un’introduzione al processamento dati usando Python, un linguaggio diprogrammazione popolare sia nell’industria che nell’ambito della ricerca. Fra le varie cose tratteremo Matplotlib.</p>'
},
{
'url': 'https://it.softpython.org/visualization/visualization-sol.html',
'contenuto' : '<h2>Visualizzazione</h2> <p>Excel ci permette di creare molti tipi di visualizzazione ma a volte è limitato, perciò useremo Python facendo grafici in Matplotlib. Matplotlib è una libreria eccezionale che consente di creare qualunque visualizzazione desideriamo. Procediamo dunque a importare matplotlib in Python:</p>'
}
]
Se l’utente cerca solo la stringa "matplotlib", visto che è presente in entrambe le pagine ci aspettiamo che vengano ritornate entrambe:
[15]:
ricerca2("matplotlib")
[15]:
[{'url': 'http://it.softpython.org',
'contenuto': '<h2>Presentazione</h2><p>Il corso SoftPython fornisce un’introduzione al processamento dati usando Python, un linguaggio diprogrammazione popolare sia nell’industria che nell’ambito della ricerca. Fra le varie cose tratteremo Matplotlib.</p>'},
{'url': 'https://it.softpython.org/visualization/visualization-sol.html',
'contenuto': '<h2>Visualizzazione</h2> <p>Excel ci permette di creare molti tipi di visualizzazione ma a volte è limitato, perciò useremo Python facendo grafici in Matplotlib. Matplotlib è una libreria eccezionale che consente di creare qualunque visualizzazione desideriamo. Procediamo dunque a importare matplotlib in Python:</p>'}]
DOMANDA: Pensiamo all’ordine delle pagine. E’ il migliore che possiamo fornire all’utente? Secondo te, qual’è la pagina che contiene più informazione riguardo Matplotlib e che andrebbe messa per prima?
Mostra risposta[16]:
pagine[0]["contenuto"].lower().count("Matplotlib".lower())
[16]:
1
[17]:
pagine[1]["contenuto"].lower().count("Matplotlib".lower())
[17]:
3
ESERCIZIO: Assegna ad ogni pagina un valore di rilevanza (relevance) , che permetta di determinare l’ordine (rank) in cui ritornare le pagine. Le pagine con rilevanza più alta devono essere presentate per prime nella lista ritornata
[18]:
# scrivi qui
Prendiamo le distanze
Un mondo di errori
Purtroppo, gli utenti non conoscono a priori il contenuto delle pagine che stanno cercando, e non sono nemmeno tutti dei letterati pignoli. Finchè cerchiamo parole che sono esattamente contenute nel testo va tutto bene:
[19]:
ricerca2('grafici')
[19]:
[{'url': 'https://it.softpython.org/visualization/visualization-sol.html',
'contenuto': '<h2>Visualizzazione</h2> <p>Excel ci permette di creare molti tipi di visualizzazione ma a volte è limitato, perciò useremo Python facendo grafici in Matplotlib. Matplotlib è una libreria eccezionale che consente di creare qualunque visualizzazione desideriamo. Procediamo dunque a importare matplotlib in Python:</p>'}]
Ma se hai provato a scrivere le tue funzioni di ricerca, ti sarai reso ben presto conto di un problema di usabilità serio: cosa succede se l’utente inserisce una stringa contenente errori di battitura, come grufici (nota la u) ? In presenza di una stringa con errori il nostro motore fallirà la ricerca:
[20]:
ricerca2('grufici')
[20]:
[]
Questo fenomeno degli errori è molto comune, pensiamo a quanti ne commettiamo specialmente quando scriviamo da dispositivi come gli smartphone.
Varie forme
In una lingua come l’italiano, il tema della presenza degli errori si interseca parzialmente col fatto che le parole possono contenere desinenze, avere forma singolare/plurale, maschile / femminile etc. Quindi se cercassimo "grafico" al singolare avremmo pure dei problemi:
[21]:
ricerca2('grafico')
[21]:
[]
Possiamo quindi chiederci cosa nella nostra mente ci fa interpretare grufici come qualcosa di simile a grafici. Proviamo a scrivere una serie di casistiche:
una lettera in meno:
grficiuna lettera in più :
graficiiuna lettera diversa:
gruficidue lettere in meno:
grfcdue lettere in più :
grraficiidue lettere diverse:
grufbciuna lettera in meno e una in più:
grficiiuna lettera diversa e una in più:
gruficiiuna lettera in meno, una diversa e una in più:
grufbcii…
DOMANDA: Quali ti sembrano le forme più simili ?
Mostra rispostaUn mondo di distanze
Guardando gli esempi sopra, ci rendiamo presto conto di come date due parole, anche molto diverse tra loro, possiamo trovare quante e quali operazioni si possono compiere per trasformarle l’una nell’altra. Minore è il numero di operazioni, maggiore ci apparirà la similarità tra le due parole.
ESERCIZIO: Immagina di piazzare una decina parole sul pavimento di una stanza, e fai un disegno (sì, con la cara e vecchia carta): prova a mettere parole simili vicine, quindi grufici sarà più vicina a grafici, mentre grufbcii sarà più lontana. grufbcii e grufici saranno un po’ più vicine tra loro. Quando la distanza è piccola, la similarità tra le parole deve essere più grande.
Se hai fatto il disegno, hai appena creato uno spazio. Però di spazi ce ne sono tanti. Tu hai disegnato su foglio, immaginando che fosse il pavimento di una stanza, che è bidimensionale. Forse avrai avuto difficoltà a piazzare alcune parole, perchè magari avevano senso vicine ad alcune ma fatalmente si trovavano vicine ad altre da cui erano molto diverse.
DOMANDA: E se potessimo appendere le parole con dei fili al soffitto ti aiuterebbe (supponi di poter scegliere per ogni parola la lunghezza del filo) ? Potrebbe servire avere più ‘spazio’?
Quale spazio
Sicuramente questa cosa delle distanze tra parole ti ha sorpreso un po’. Noi siamo abituati alle distanze nel nostro mondo fisico, per esempio sappiamo dire se un oggetto è fisicamente vicino ad un altro. Però spesso anche nella quotidianità usiamo la distanza in modo figurativo, per esempio diciamo se una persona è vicina ad un’altra quando ne condivide i sentimenti, magari in un momento di difficoltà.
Quando si parla di distanze, bisogna imperativamente considerare tre cose:
gli oggetti che vogliamo considerare
lo spazio in cui misuriamo
un sistema di misura con cui per l’appunto misuriamo le distanze.
Vediamo degli esempi.
Distanza tra stringhe
Quella che abbiamo visto sulle stringhe si chiama anche distanza di edit. Vediamo le caratteristiche:
oggetti: stringhe
spazio: tutte le possibile stringhe (anche quelle senza senso, e anche la stringa vuota)
misura di distanza: numero di caratteri da modificare per trasforamare una stringa in un’altra
Distanza fisica tra oggetti nel piano
Se abbiamo un oggetto \(p\) nella stanza e vogliamo arrivare ad un oggetto \(q\) in un altro punto, possiamo facilmente calcolare quanti passi ci servono. Se abbiamo un metro, possiamo anche essere più precisi:
oggetti: cose del mondo fisico (bisogna decidere quali, si potrebbe considerare solo quelli con peso > 1 Kg)
spazio: spazio euclideo
misura di distanza: distanza euclidea

Distanza nel mondo
Qua le cose si fanno più complicate.
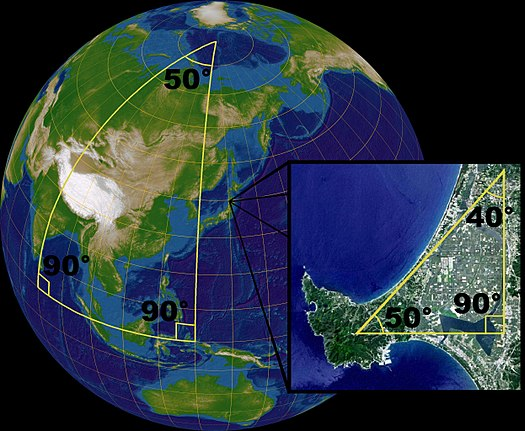
DOMANDA: Se sei in Italia e vuoi arrivare in Giappone, vai in linea retta? Attenzione: se rispondi sì ti servirà una trivella molto potente :-)
oggetti: cose del mondo fisico (bisogna decidere quali, si potrebbe considerare solo quelli con peso > 1 Kg)
spazio: spazio sferico (2D o 3D)
misura di distanza: curva geodetica
Quando si considerano distanze nel mondo, bisogna tener conto che la Terra è sferica, lo sanno bene navigatori e piloti. Non si può andare in linea retta, ma invece muoversi lungo la superficie della sfera (vedi Wikipedia). Questo di fatto aumenta le distanze:
Ricerca a prova di errore
Possiamo migliorare il nostro motore di ricerca per renderlo più usabile anche in presenza di errori da parte dell’utente?
DOMANDA: supponi di avere bella pronta una funzione distanza_stringhe che date due stringhe ti dice quanti caratteri occorrono per trasformare una stringa in un altra. Sfruttando questa funzione, riusciresti a migliorare il motore di ricerca ?
La distanza di Levenshtein
Il matematico Russo Vladimir Levenshtein ha trovato il modo di calcolare rapidamente la distanza tra stringhe che ora prende il suo nome. Fortunamente per noi, ci sono parecchie implementazioni Python già pronte. Non ci addentreremo nell’implementazione, per capirla bene servirebbe un corso apposito di algoritmi:
[22]:
# ATTENZIONE: NON E' NECESSARIO CHE COMPRENDI COME FUNZIONA QUESTO CODICE !
# CI LIMITEREMO SOLO A UTILIZZARE QUESTA FUNZIONE !!
# tratto da https://stackabuse.com/levenshtein-distance-and-text-similarity-in-python/
def distanza_stringhe(s, t):
"""
iterative_levenshtein(s, t) -> ldist
ldist is the Levenshtein distance between the strings
s and t.
For all i and j, dist[i,j] will contain the Levenshtein
distance between the first i characters of s and the
first j characters of t
"""
rows = len(s)+1
cols = len(t)+1
dist = [[0 for x in range(cols)] for x in range(rows)]
# source prefixes can be transformed into empty strings
# by deletions:
for i in range(1, rows):
dist[i][0] = i
# target prefixes can be created from an empty source string
# by inserting the characters
for i in range(1, cols):
dist[0][i] = i
for col in range(1, cols):
for row in range(1, rows):
if s[row-1] == t[col-1]:
cost = 0
else:
cost = 1
dist[row][col] = min(dist[row-1][col] + 1, # deletion
dist[row][col-1] + 1, # insertion
dist[row-1][col-1] + cost) # substitution
#debug
#for r in range(rows):
# print(dist[r])
return dist[row][col]
Proviamola:
[23]:
distanza_stringhe("grafici", "grufici")
[23]:
1
[24]:
distanza_stringhe("grafici", "grfici")
[24]:
1
[25]:
distanza_stringhe("grafici", "gruficii")
[25]:
2
[26]:
distanza_stringhe("grafici", "grufbcii")
[26]:
3
Ricerca per distanza sintattica
Questa funzione distanza_stringhe pare faccia al caso nostro !
ESERCIZIO: Prendendo codice dalla funzione ricerca2, crea una funzione ricerca3 che restituisca risultati anche con stringhe di input aventi una distanza di Levenshtein <= 2 dalle parole corrette nel testo delle pagine:
supponi che in input siano date parole singole
ricordati delle pagine in cui hai già trovato una corrispondenza usando un insieme di url con la struttura dati set
Separa le parole nel testo delle pagine con la funzione split:
[27]:
"il testo della mia pagina".split(" ")
[27]:
['il', 'testo', 'della', 'mia', 'pagina']
[28]:
# scrivi qui
[29]:
ricerca3('grafico')
[29]:
[{'url': 'https://it.softpython.org/visualization/visualization-sol.html',
'contenuto': '<h2>Visualizzazione</h2> <p>Excel ci permette di creare molti tipi di visualizzazione ma a volte è limitato, perciò useremo Python facendo grafici in Matplotlib. Matplotlib è una libreria eccezionale che consente di creare qualunque visualizzazione desideriamo. Procediamo dunque a importare matplotlib in Python:</p>'}]
[30]:
ricerca3('grufici')
[30]:
[{'url': 'https://it.softpython.org/visualization/visualization-sol.html',
'contenuto': '<h2>Visualizzazione</h2> <p>Excel ci permette di creare molti tipi di visualizzazione ma a volte è limitato, perciò useremo Python facendo grafici in Matplotlib. Matplotlib è una libreria eccezionale che consente di creare qualunque visualizzazione desideriamo. Procediamo dunque a importare matplotlib in Python:</p>'}]
[31]:
ricerca3('gruficii')
[31]:
[{'url': 'https://it.softpython.org/visualization/visualization-sol.html',
'contenuto': '<h2>Visualizzazione</h2> <p>Excel ci permette di creare molti tipi di visualizzazione ma a volte è limitato, perciò useremo Python facendo grafici in Matplotlib. Matplotlib è una libreria eccezionale che consente di creare qualunque visualizzazione desideriamo. Procediamo dunque a importare matplotlib in Python:</p>'}]
[32]:
ricerca3('grufbcii') # distanza = 3 > 2
[32]:
[]
Similarità semantica
Il calcolo della similarità di testi è uno strumento potente per costruire rapidamente sistemi di ricerca intelligenti.
Finora abbiamo visto la similarità sintattica, cioè abbiamo guardato i singoli caratteri. Ma ovviamente un testo non è solo una sequenza di caratteri, per noi è una sequenza di parole con significato. Il ramo della Data science che si occupa del significato delle parole è la semantica . Nel contesto del web, possiamo parlare di Semantic web
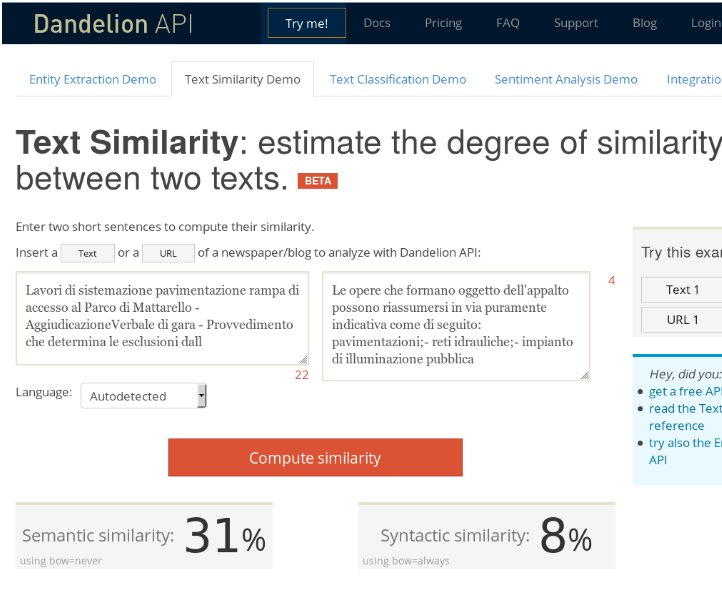
Vediamo di sfruttare i significati nel testo. Per esempio, pensiamo ad un’impresa che dopo aver trovato un bando di gara interessante pubblicato dal Comune di Trento. potrebbe voler cercare bandi o avvisi simili , per esempio per capire quali sono stati i criteri di selezione e per individuare quanti e quali potenziali aziende concorrenti hanno partecipato al bando. Per comprendere con metodi automatici quanto il testo di un bando assomigli ad un’altro, si potrebbero usare i servizi di text similarity offerti da Dandelion dell’azienda SpazioDati.
Un servizio di text similarity prende due testi e calcola un valore di similarità come un numero da 0.0 a 1.0. In questo
esempio viene mostrato come venga rilevata una qualche
somiglianza tra due testi che trattano di pavimentazione stradale.
Ricerca veloce
Al fine di avere un servizio di ricerca di similarità veloce, ogni volta che viene effettuata una ricerca non conviene confrontare il testo con tutti gli altri n-1 , perché potrebbe via potenzialmente parecchio tempo e l’utente nel frattempo potrebbe stufarsi. Una ottimizzazione potrebbe essere precalcolare tutte le similarità necessarie al momento dell’ottenimento i dati, costruendo una tabella di similarità. Così, quando un utente ci indica un testo, possiamo cercare rapidamente nella
nostra tabella quali sono i testi maggiormente simili, senza più nemmeno usare il servizio di similarità. La tabella può avere la forma di una matrice diagonale come la seguente. Supponendo di avere n=4 testi, chiameremo il servizio di similarità per riempire solo le celle nella parte superiore così:
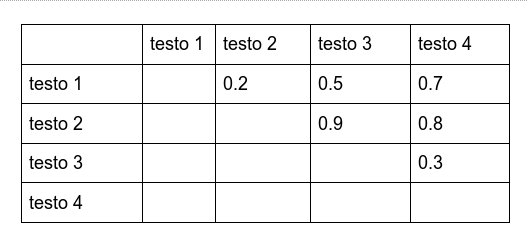
Per riempire la prima riga serviranno n - 1 confronti, per la seconda n - 2, per la terza n - 3 e così via.
In totale le chiamate al servizio di text similarity saranno
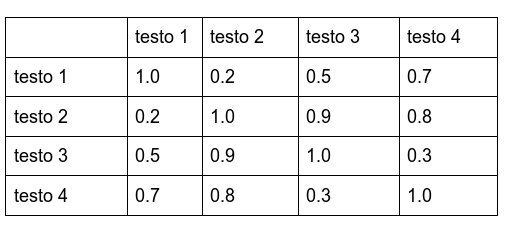
Una volta ottenuta la tabella sopra, i restanti valori si possono calcolare rapidamente sapendo che un testo ha sempre similarità 1.0 con se stesso e gli altri valori si possono ricavare per simmetria lungo la diagonale. Qua li abbiamo scritti per motivi di chiarezza, ma di fatto non serve nemmeno materializzarli in memoria:
Il prezzo del successo
Fatta la startup, dopo la geniale idea della tabella per avere ricerche veloci, abbiamo trovato i primi utenti in Trentino e sono entusiasti del nostro servizio. Convinciamo anche dei venture capitalist a investire denaro sonante nella nostra impresa. Ebbri di successo, pensiamo al futuro radioso: è tempo di conquistare il mondo intero.
Mentre pensiamo beati al prossimo modello di Lambo da comprare, all’improvviso una domanda sfreccia nella nostra testa come un fulmine, incenerendo senza pietà l’auto dei nostri sogni:
Ma l’algoritmo scala?
Una volta che abbiamo la tabella possiamo fare ricerche molto più rapide, ma se avessimo un miliardo di bandi da analizzare, quante celle ci sarebbero nella tabella risultante ? Quali sarebbero le conseguenze?
Per oggi, ci fermiamo qui con l’ottimizzazione. Quanto segue è solo un invito a pensare ai big data e a cosa implicano.
Di solito si analizzano il tempo e lo spazio:
Tempo: supponendo che ci voglia 1 secondo al servizio di similarità per calcolare ogni similarità, quanto tempo ci metterebbe a riempire la tabella superiore in minuti, ore, giorni, ….?
Spazio: Supponendo per semplicità che ogni cella occupi un byte, e sapendo che un gigabyte sono un miliardo di byte (1.000.000.000):
quanti byte ci servirebbero?
Che unità di misura useremmo? Puoi consultare Wikipedia per trovare il nome giusto.
Secondo te sarebbe realistico salvare la tabella in un solo server?
Se usassimo solo la parte superiore della tabella, ridurremmo sostanzialmente lo spazio occupato ?
DOMANDA: (solo da pensare, niente implementazione !!) Riesci ad immaginare qualche alternativa alla tabellona ? Suggerimento: Se un pino è simile ad un abete nano, e l’abete nano è simile ad un cespuglio, possiamo dire qualcosa sul grado di similarità tra il pino e il cespuglio ?
[ ]: